Documentation
OmniRun
Documentation
Isolated virtual machines for AI agents. One API call to create, one to destroy. Every sandbox boots in under a second and runs its own kernel.
import { Sandbox } from '@omnirun/sdk';
const sandbox = await Sandbox.create('playground', {
timeout: 300,
});
// sandbox.sandboxId → "sb_a1b2c3d4"Quick Start
5-step walkthrough
Go from zero to running code in an isolated VM. Each step builds on the previous. The entire flow takes about 60 seconds. Available for TypeScript and Python.
npm install @omnirun/sdkawait sandbox.files.write('/tmp/data.csv', content)await sandbox.kill()TypeScript SDK
Installation & auth
Install the SDK and set your API key. The SDK automatically reads OMNIRUN_API_KEY from your environment.
All methods return typed responses. The SDK supports both ESM and CommonJS.
Run in playground →npm install @omnirun/sdkREST API
Endpoints
All endpoints require a Bearer token. Base URL: https://api.omnirun.io
| Method | Endpoint | Description |
|---|---|---|
| Sandboxes | ||
| POST | /sandboxes | Create a new sandbox |
| GET | /sandboxes | List active sandboxes |
| GET | /sandboxes/:id | Get sandbox status |
| DELETE | /sandboxes/:id | Terminate sandbox |
| Commands | ||
| POST | /sandboxes/:id/commands | Run a command |
| GET | /sandboxes/:id/commands | List executed commands |
| Files | ||
| POST | /sandboxes/:id/files | Upload a file |
| GET | /sandboxes/:id/files | Read a file (path as query param) |
| Exposures | ||
| POST | /sandboxes/:id/exposures | Expose a port with preview URL |
| GET | /sandboxes/:id/exposures | List active exposures |
| DELETE | /sandboxes/:id/exposures/:eid | Remove an exposure |
| LLM Proxy | ||
| POST | /llm/v1/chat/completions | OpenAI-compatible chat completion |
| GET | /llm/v1/models | List available models |
| GET | /llm/v1/usage | Get spend tracking info |
| Vault | ||
| POST | /vault/init | Initialize user vault |
| POST | /vault/credentials | Store a credential |
| GET | /vault/credentials | List stored credentials |
| Auth | ||
| POST | /auth/magic-link/request | Request a magic link email |
| POST | /auth/otp/verify | Verify OTP code |
| GET | /auth/me | Get current user info |
| POST | /auth/tokens | Create an API token |
| History | ||
| GET | /sandboxes/history | List past sandbox sessions |
Platform
Vault
Secure credential storage with per-user isolation. Store API keys and secrets in your vault, then inject them into sandboxes at creation time.
When vaultInject: true is set, all vault credentials are written to /tmp/.omnirun-env inside the sandbox and automatically sourced by the agent process. Vault sandboxes are exempt from idle auto-kill.
curl -X POST https://api.omnirun.io/vault/init \
-H "Authorization: Bearer $OMNIRUN_KEY"
// Auto-created on first logincurl -X POST https://api.omnirun.io/vault/credentials \
-H "Authorization: Bearer $OMNIRUN_KEY" \
-d '{"key": "OPENAI_API_KEY",
"value": "sk-..."}'const sandbox = await Sandbox.create('playground', {
vaultInject: true,
});
// Credentials written to /tmp/.omnirun-env
// Auto-sourced by the sandbox agentIntegration
Claude Managed Agents
Anthropic runs the agent loop and model; every tool call (bash, read, write, edit, glob, grep) executes inside an isolated OmniRun microVM on your infrastructure. A worker polls Anthropic's work queue and, for each claimed session, spawns a fresh claude-agentsandbox (8 GB, restored from snapshot in a few seconds).
1. Create a self_hosted environment in the Anthropic Console and generate an environment key. 2. Run the worker (shown here) on your box. We ship a claude-worker systemd unit that polls with graceful drain on restart. 3. Point a session at that environment — its tool calls now run in your microVMs.
Never set ANTHROPIC_API_KEYon the worker — the spawner refuses to start if it's present, so it can never reach a sandbox. Only the scoped ANTHROPIC_ENVIRONMENT_KEY is forwarded into the VM.
# Install Anthropic's worker CLI (ant)
curl -fsSL .../ant_1.10.0_linux_amd64.tar.gz \
| tar -xz -C /usr/local/bin ant
# Env from your self_hosted environment (Console)
export ANTHROPIC_ENVIRONMENT_KEY=sk-ant-oat01-...
export ANTHROPIC_ENVIRONMENT_ID=env_...
# Each claimed session runs in a fresh microVM
ant beta:worker poll --on-work ./spawn.shspawn.sh — per-session launcher
ant invokes your spawn script once per claimed session, passing ANTHROPIC_SESSION_ID / ANTHROPIC_WORK_ID. It creates the microVM, starts ant beta:worker run inside, polls until the session exits, then tears the sandbox down. Customize template, env, concurrency cap, and egress here.
Egress — open by default
Agent sandboxes get full outbound by default — real agents need package registries and git. To lock a deployment down, set sniProxy: true with allowDomains in the create body; the SNI proxy then forwards only allow-listed hosts. It blocks everything else (including pypi/npm), so list what you need.
Session lifecycle
One microVM per session, one snapshot restore per spawn. Tool calls within a session share that VM; disk does not persist across sessions (no Persistent Memory yet). Outputs under /mnt/session/outputs can be copied back to the host before teardown.
Troubleshooting
Restarting the worker drains in-flight sessions (generous TimeoutStopSec). Run one poller per box — stray ant beta:worker poll processes compete for work. A per-template concurrency cap protects host RAM; sessions over the cap are deferred, not dropped.
Platform
Limits
Each user can run up to 3 concurrent sandboxes by default. Creating a sandbox beyond this limit returns a 429 status code.
Sandboxes with no activity for 15 minutes are automatically killed. Sandboxes created with vaultInject: true are exempt from idle auto-kill.
// Concurrent sandbox limit: 3 per user
// Exceeding the limit returns HTTP 429
POST /sandboxes
// → 429 { "error": "concurrent sandbox limit reached" }
// Idle auto-kill: 15 minutes with no activity
// Vault-injected sandboxes are exemptPlatform
Networking
Sandboxes have no internet access by default. With internet: falsea sandbox is a true L3 air-gap — there's no route out at all. Set internet: true for full outbound egress.
The air-gap prevents data exfiltration for workloads that don't need the network. For workloads that need some outbound, an opt-in SNI egress proxycan restrict a sandbox to an allow-list of hosts — it inspects each TLS handshake and only forwards connections whose server name matches your list, dropping the rest. It is off by default and, when on, blocks every host not listed (including package registries).
Read security model →const sandbox = await Sandbox.create('agent', {
internet: false
});
// internet: false → true L3 air-gap, no route out
// internet: true → full outbound egress
// per-domain: opt-in SNI allow-list (sniProxy)Platform
Templates
Templates define the pre-installed packages and base configuration for a sandbox. Use built-in templates or create your own.
Try playground templates →// Built-in templates
'playground' // General purpose
'rust' // Rust toolchain
'typescript' // Node.js + TS
'javascript' // Node.js
'php' // PHP 8.x
'sql' // PostgreSQL
'zig' // Zig compiler
'claude-agent' // Claude Managed Agents (8 GB)
// Custom template
const sb = await Sandbox.create('my-custom-template');Platform
Desktop Sandbox
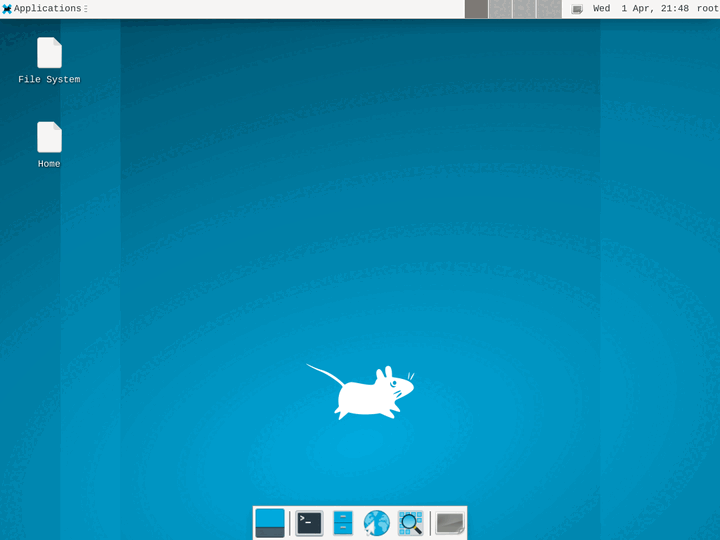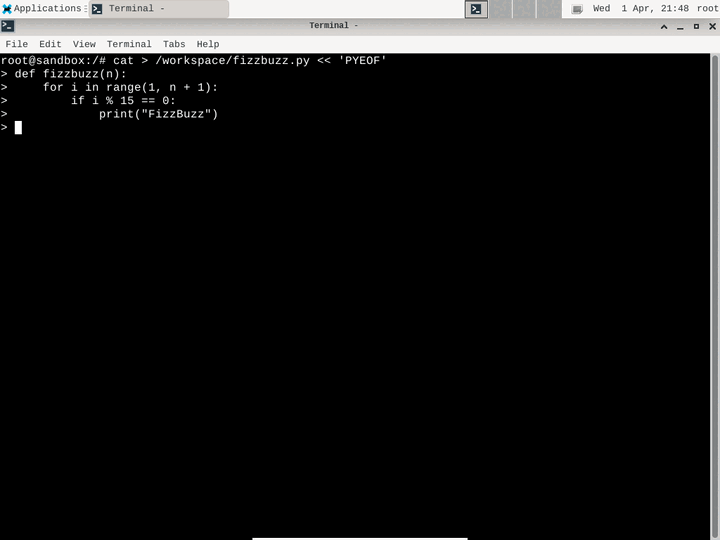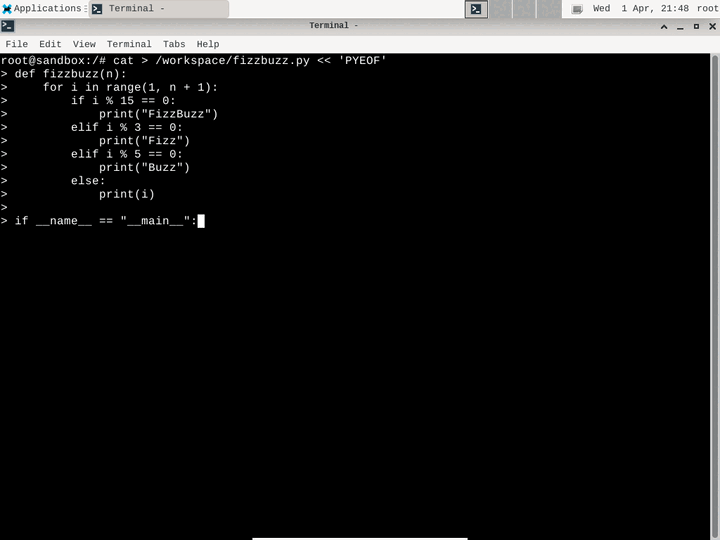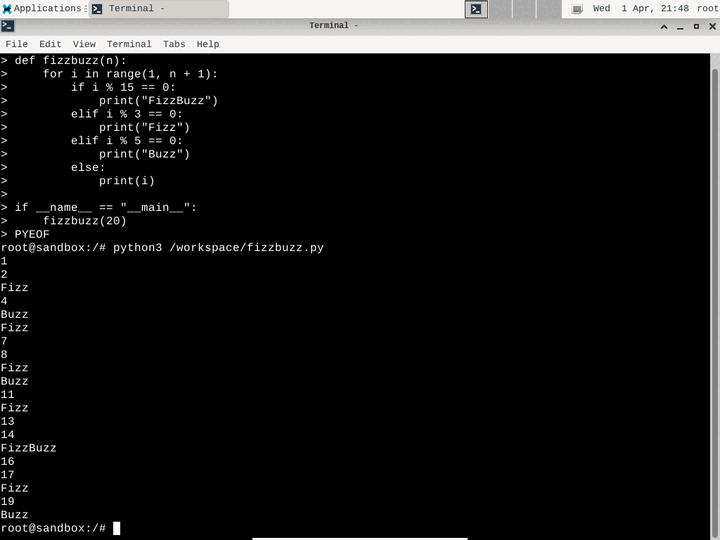
Run a full Linux GUI desktop (XFCE) inside a Firecracker microVM. Control the desktop programmatically with mouse clicks, keyboard input, and screenshots — perfect for AI computer use, visual testing, and GUI automation. Available in both TypeScript and Python SDKs.
View examples →const sb = await Sandbox.create('desktop');
// Take a screenshot
const png = await sb.desktop.screenshot();
// Click, type, and press keys
await sb.desktop.leftClick(512, 384);
await sb.desktop.type('hello world');
await sb.desktop.press('Return');
// Get screen info
const screen = await sb.desktop.getScreen();
// { width: 1024, height: 768 }
| screenshot() | Capture the desktop as PNG |
| leftClick(x, y) | Click at coordinates |
| rightClick(x, y) | Right-click at coordinates |
| doubleClick(x, y) | Double-click at coordinates |
| type(text) | Type text character by character |
| press(key) | Press a key or combo (e.g. "ctrl+c") |
| moveMouse(x, y) | Move cursor to coordinates |
| scroll(dir, amount) | Scroll up/down/left/right |
| drag(x1, y1, x2, y2) | Drag from one point to another |
| getScreen() | Get resolution and cursor position |
| getStreamInfo() | Get noVNC connection details |
Live Desktop Streaming
Every desktop sandbox runs noVNC on port 6080. Create a preview URL with sandbox.expose(6080) to get a shareable link for live desktop viewing in any browser — no VNC client needed.
Reference
Security Model
OmniRun uses Firecracker microVMs for hardware-level isolation. Each sandbox runs its own Linux kernel, unlike containers which share the host kernel.
Full security overview →// Isolation layers (top → bottom)
'Your Code' // Userspace
'Guest Kernel' // Dedicated per sandbox
'microVM' // Minimal VMM
'KVM' // Hardware virtualization
'Host OS' // Hardened hostReference
Benchmarks
MicroVM boot times compared to traditional containers and full VMs. OmniRun sandboxes boot in under a second.
Median of cold-start measurements on Hetzner AX102 bare metal. 1,000 runs.